La espectroscopía de infrarrojo cercano (NIR), que normalmente utiliza fuentes halógenas de luz blanca, se emplea en la industria agroalimentaria para recuperar información sobre la composición química y los parámetros de calidad de diferentes productos (frutas y verduras, vino o carne, entre otros) de forma no invasiva, rápida y precisa, lo que supone una ventaja frente a los métodos de medida convencionales.
Sin embargo, las relaciones entre las medidas espectrales y los parámetros de calidad no son triviales, y se emplean diferentes métodos de machine learning para modelarlas. En este post se proporcionará una descripción general de los métodos de calibración comúnmente empleados basados en el machine learning.
Hay dos tipos principales de algoritmos de machine learning: algoritmos supervisados y algoritmos no supervisados. También existen algoritmos semisupervisados, que son una mezcla de ambos. En el caso de los algoritmos supervisados, un humano «enseña» a los algoritmos las salidas que corresponden a ciertas entradas (estas parejas se denominan datos etiquetados) para que puedan predecir las salidas que corresponden a nuevas entradas. Estos algoritmos pueden tener dos propósitos: clasificación, es decir, organizar productos u objetos en diferentes clases según sus características; o regresión, es decir, recuperar el valor de una propiedad determinada como la concentración de un parámetro bioquímico (proteínas, lípidos, azúcares).
En el caso de los algoritmos no supervisados, no hay intervención humana. Los algoritmos intentan detectar patrones basados en un conjunto de datos sin etiquetar. Estos algoritmos suelen ser útiles cuando la persona no sabe qué buscar en los datos. Existen dos tipos principales de algoritmos: los algoritmos de agrupamiento, cuyo propósito es clasificar los datos en grupos según su similitud; y algoritmos de asociación, cuyo objetivo es encontrar reglas dentro del conjunto de datos.
En los siguientes párrafos, se describen los conceptos básicos de cuatro algoritmos de machine learning: análisis de componentes principales (Principal Component Analysis, PCA), máquina de vectores de soporte (Support Vector Machine, SVM), regresión de mínimos cuadrados parciales (Partial Least Squares regression, PLS) y redes neuronales (Artificial Neural Networks, ANN).
El análisis de componentes principales (PCA) es un método no supervisado que reduce la dimensionalidad de los datos iniciales pero conserva la varianza. Los datos iniciales se transforman en variables independientes denominadas componentes principales (principal components, PC), donde cada componente es una combinación lineal de los datos originales. El número de componentes principales es igual al número de variables originales, pero las primeras componentes explican la mayor parte de la varianza, lo que permite la reducción de la dimensionalidad. Un PCA permite mostrar la estructura inherente de los datos.
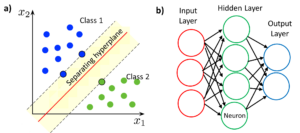
Support Vector Machine (SVM) es un algoritmo supervisado ampliamente utilizado para la clasificación de las muestras. El propósito de este algoritmo es encontrar un hiperplano en un espacio N-dimensional (siendo N el número de variables) que clasifica por separado dos conjuntos de puntos de datos. Si el número de variables es 2, el hiperplano es una línea; y si el número de variables es 3, el hiperplano es un plano bidimensional. El mejor hiperplano para un caso dado es el que obtiene el máximo margen entre las dos clases. Los algoritmos de SVM utilizan funciones del kernel para transformar el espacio original en un espacio de mayor dimensión donde la separación de clases es más fácil. SVM también se puede adaptar para la clasificación multiclase (más de 2 clases).
La regresión de mínimos cuadrados parciales (PLS) es un método para desarrollar modelos predictivos cuando hay una gran cantidad de variables (factores) y estas son altamente colineales. PLS emplea información de todas las longitudes de onda del espectro NIR para predecir la composición de la muestra, en lugar de utilizar unas pocas longitudes de onda seleccionadas. El objetivo de PLS es utilizar los factores para predecir las respuestas. Esto se logra indirectamente al extraer las variables latentes T y U de los factores y respuestas muestreados, respectivamente. Las variables extraídas T (también denominadas proyecciones de X) se emplean para predecir las proyecciones de Y (U) y estas proyecciones de Y se utilizan para predecir las respuestas.
Una red neuronal (ANN) es un modelo de machine learning que imita el funcionamiento de las neuronas en un cerebro biológico. La red neuronal contiene nodos (neuronas) organizados en varias capas. Hay una capa de entrada y una capa de salida que se pueden conectar directamente o a través de una o más capas ocultas. La salida de cada neurona se calcula como una función no lineal de la suma de sus entradas y se envía a todos los nodos de la siguiente capa después de aplicar un coeficiente o peso. Estos pesos se ajustan mediante el entrenamiento de la red neuronal. Las principales ventajas de las redes neuronales son que no requieren el desarrollo de un modelo explícito y que el fallo de una de las neuronas no afecta al funcionamiento del sistema.
En conclusión, la combinación de la espectroscopía NIR con algoritmos de machine learning juega un papel clave en la consolidación de la espectroscopía NIR como una herramienta no invasiva, no destructiva y rápida para el análisis de la calidad de los alimentos. En este post se describen algunos de los algoritmos más conocidos, aunque existen muchos más.
Escrito por J.J. Imas
Bibliografía
[5] «Support-vector machine – Wikipedia,» https://en.wikipedia.org/wiki/Support-vector_machine
[7] «Artificial neural network – Wikipedia,» https://en.wikipedia.org/wiki/Artificial_neural_network